[:fr]
 1983 Michael chante Billie Jean avec un accessoire inattendu.
1983 Michael chante Billie Jean avec un accessoire inattendu.

Le gant pailleté blanc, accessoire est aussi mythique que la canne de Patrick Hernandez.
Il en va de même du Role Mining. A la fois mythe et accessoire indispensable.
Une histoire qui commence en 1992 avec le dépôt par le NIST du modèle RABC. Une grande avancée dans la gestion des accès, mais rapidement un enfer pour créer ces fameux rôles. Rôles à plat, rôles hiérarchiques, qui ne s’est pas cassé le nez à mettre au point ces modèles.
Dans l’image jointe on positionne clairement le nœud du problème:
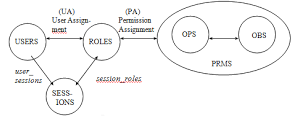
- A droite le monde du SI
- A gauche les identités
- Entre les deux une seule double flèche (PA)
Toute la difficulté repose sur cette liaison, comment associer deux natures de données et d’organisation d’une manière efficace ?
Top-down & Bottom-up
La flèche PA doit être parcourue dans les deux sens (en UML un trait suffit ;-), c’est le sens des démarches d’analyse classiques en Role Mining.
- Soit on part de l’organisation des identités et on descend dans le SI
- Soit on remonte du SI vers les comptes et les utilisateurs
Mais quelle que soit la démarche il faut en premier collecter et qualifier les données. Car la démarche de Role Mining s’appuie fondamentalement sur des données, ce qui en fait sa proximité avec le DataMining.
 Donc la première des activités c’est de “pomper” les données et c’est l’une des plus longue.
Donc la première des activités c’est de “pomper” les données et c’est l’une des plus longue.
Car il faut la corréler, la commenter, la clarifier. En bref, en faire une information. La difficulté n’est pas du côté des identités, même si on retrouve toujours son lot d’homonymes et de fautes d’orthographe, de références perdues à des organisations obsolètes. Le point dur sont les applications et ceux pour plusieurs raisons:
- Chaque application peut avoir son approche
- Les connaissances disparaissent aussi vites que les équipes projets
- L’inventivité trouve toujours sa place pour tordre les modèles
Si nous retournons sur la définition du NIST on voit qu’une permission est une opération sur un objet. Effectivement j’ai le droit de lire le fichier XXX, c’est une permission. Mais comment ai-je obtenu cette permission ? Comment vais-je remonter cette information afin de l’exploiter en vue d’une recherche de rôle ?
Habilité vs Habilitant
Dans ma pratique du sujet, j’ai développé le concept d’habilitant. Cette notion vient de la linguistique, c’est l’association Signifiant / Signifié. Pour m’exprimer, j’ai un support qui porte du sens. Le sens est le Signifié, le support le Signifiant. Pour le Role Mining la matière, le support se sont les données qui caractérisent l’habilitation (ou accréditation) donc l’habilitant. Pour la majorité des applications l’habilitant est composé :
- D’un compte, c’est le lien vers l’identité
- D’une application, c’est une notion facilement compréhensible par tous
- D’un sujet, cette notion recouvre les droits, profils, pouvoirs, associé à l’application et obtenue au profit du compte
- D’un objet, cette notion est optionnelle mais peut-être très riche. Implicitement, l’objet pourrait être les données de l’application, mais en terme d’autorisation c’est la notion de périmètre qui est pertinente. Oui j’ai accès au système RH pour modifier les payes, mais les payes de qui ? C’est cette notion de périmètre que je place dans l’objet.
Chercher ou trouver telle est la question ?
Le Role Mining part avec deux handicaps:
- La nature des données n’est pas adaptée aux méthodes statistiques les plus puissantes
- Il n’existe pas de moyen d’obtenir une solution exacte
Les données que nous manipulons sont principalement du texte, donc qualitatives. S’il y était possible de transformer les habilitants en coordonnées dans un espace à « n » dimensions on pourrait faire du calcul de barycentre et proposer des regroupements. Mais quelle est la position dans cet espace de GGESEC ou AssDR ?
Heureusement il nous reste l’analyse descriptive, qui répond à la question « combien » :
- Combien d’identité ?
- Combien de compte ?
- Combien d’habilitant pour cette fonction métiers ?
A partir de ces comptages nous allons proposer des solutions qui représentent la norme des habilitants pour une catégorie. Mais comment évaluer cette solution ? Est-ce la bonne, si je change un habilitant ou une identité ma solution reste-t-elle pertinente ?
Un des problèmes du comptage c’est qu’il globalise une information mais que vaut cette norme pour les données d’un individu ?
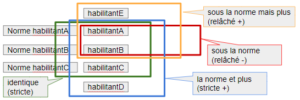 On constate quatre natures d’écart:
On constate quatre natures d’écart:
- En vert pas d’écart
- En rouge sous la norme
- En Bleu plus que la norme
- En Orange en partie la norme
Prenons un exemple concret et évaluons des solutions. Dans le tableau nous confrontons des solutions avec plusieurs habilitants en nombre croissant à une population de moins de 500 individus. Pour chaque solution nous mesurons les quatre écarts que nous avons identifiés préalablement.
Ce qui est frappant c’est que pour des combinaisons différentes d’habilitant les écarts varient énormément. Cette combinatoire est une part importante du problème en plus de celui d’une définition de l’évaluation.
| Nb habilitant |
1 |
2 | 2 | 2 | 3 | 4 |
7 |
| Stricte |
0 |
0 | 0 | 0 | 0 | 0 |
134 |
|
Stricte + |
468 | 0 | 146 | 3 | 0 | 0 |
0 |
| Relâché + |
0 |
433 | 32 | 497 | 468 | 405 |
12 |
| Relâché – |
0 |
0 | 0 | 0 | 29 | 93 |
352 |
Ce que nous recherchons comme solution, c’est une base commune à une population, donc un des indicateurs important est « Stricte ». Mais cet indicateur est trop restrictif, il est possible de l’assouplir avec « Relâché -« .
Pour établir un classement avec deux critères nous utilisons la comparaison lexicographique:
| Solution 1 | Solution 2 | Solution 3 | |
|---|---|---|---|
| nbIdntStrict = 1 nbIdntRel- = 1 |
nbIdntStrict = 1 nbIdntRel- = 0 |
nbIdntStrict = 0 nbIdntRel- = 2 |
On compare les critères dans l’ordre: Solution 1 et 2 ex-aequo sur le premier Sur le deuxième critère Solution 1 domine et remporte la comparaison |
Franchir un tabou
A partir de la solution locale, trouvée avec une première heuristique (analyse descriptive), nous allons rechercher dans son voisinage une meilleure solution , en appliquant un algorithme d’optimisation (méta heuristique). Nous avons retenu la recherche Tabou.
Le principe de Tabou est de générer des solutions, les évaluer, aller vers les meilleures (sans revenir sur ses pas). Mais si on n’avance pas assez, on peut reprendre une ancienne position (transgresser le tabou) et repartir sur une nouvelle voie.
Avec ce moyen nous explorons le monde des possibles et identifions des moyens de progresser ou affermir une solution.
Il y aura encore beaucoup à dire sur ce sujet en particulier sur la communication et l’élaboration finale des politiques d’habilitation, mais cela fera l’objet d’un prochain article…
[:]




