| Introduction à la notion de cyber-résilience
Contexte
Avec l’ajout de la dimension cyber, les théories classiques de la résilience ont été bousculées.
Au-delà des abus de langage qui sont le fait des phénomènes de modes, et qui emploient le terme cyber de manière galvaudée, le sujet mérite d’être analysé, rationalisé et dédramatisé.
D’après la publication de l’ENISA de janvier 2019 [1] référençant les 15 attaques constituant les plus grandes menaces, on peut noter le nombre grandissant d’attaques internes. Les menaces ont donc évolué et se protéger des DDOS ou autres menaces classiques n’est plus suffisant au regard des APT de plus en plus complexes. Notamment, lorsqu’une APT est découverte ou se déclenche, la plupart du temps, les pirates auront pris le soin de corrompre ou d’infecter les sauvegardes du SI au préalable. Si l’on ne prévoit pas ces situations, les pertes engendrées seront colossales et la durée de reconstruction du système d’information de l’entreprise pourra être comptée en nombre de mois pendant lesquels l’activité sera stoppée ou en mode dégradé.
Changement de paradigme
Avec la protection périmétrique du château fort, on considérait uniquement le risque venant de l’extérieur. Cette notion est maintenant dépassée, et actuellement, on parle de défense en anneau qui résulte de la combinaison de différentes mesures et qui permet de réduire le risque à tous les niveaux du SI. Cet adage de Robert Mueller, ancien directeur du FBI, illustre bien cette actualité où les APT ne sont plus un mythe : « Zero trust even inside ».
Les concepts de base de la résilience doivent être respectés tout en intégrant ces nouvelles données. Par exemple, nombre de Datacenter sont pourtant Tier IV et garantissent la tolérance aux pannes. Malgré la complexité des infrastructures mises en place, elles restent souvent reliées sur un même LAN. Ceci ne garantit pas d’être protégé en cas de corruption des infrastructures une fois que l’attaque aura passé la protection périmétrique et ne permettra pas de reconstruire le SI rapidement de facto, puisque l’on ne pourra pas compter sur les données sauvegardées.
Qu’est-ce la cyber-résilience ?
Si l’on se réfère à la définition édictée par le NIST, la cyber-résilience est définie comme ” la capacité d’anticiper, de résister, de récupérer et de s’adapter à des conditions défavorables, de stress, des attaques ou des compromis sur des systèmes qui incluent des cyber-ressources “. Cette définition peut s’appliquer à diverses entités, comme un système, un service partagé, une infrastructure commune, une organisation voire une nation.
| Principes
Principes généraux et références
NIST « National Institute of Standards and Technology » a publié un modèle visant à améliorer la cyber sécurité des infrastructures critiques, nommé « Cybersecurity Framework ». [2]. A travers ce modèle, le NIST rappelle 5 grands principes qui sont l’identification, la protection, la détection, la réponse et la restauration.
Récemment, en novembre 2019, le NIST a fait une publication qui concerne directement la cyber-résilience. [3]
Le MITRE [4] fixe les objectifs de la cyber-résilience comme étant les suivants :
Anticiper : maintenir un état de préparation éclairé afin de prévenir les compromissions.
Résister : maintenir les fonctions essentielles métier malgré l’exécution réussie d’une attaque par un adversaire.
Restaurer : restaurer les fonctions essentielles métier dans toute la mesure du possible après l’exécution réussie d’une attaque.
Évoluer : pour adapter les cyber-capacités de soutien, afin de minimiser les impacts négatifs des attaques.
Le MITRE établit aussi des principes directeurs qui pourront être utilisés dans la phase de design.
Les documents produit par le NIST et le MITRE apportent une grande méthodologie, ils doivent être adaptés à la maturité et à la complexité du SI de l’entreprise concernée. Le travail de l’architecte deviendra donc primordial afin d’avoir un design adapté aux problématiques de cyber-résilience. [4]
Principes inconditionnels
Quoiqu’il en soit, parler de cyber-résilience n’empêche pas d’appliquer les principes généraux de sécurité comme une bonne hygiène, un bon patch management, une bonne politique de gestion des droits, un bon référencement des actifs et leur durcissement. C’est ce que l’on appelle communément la ” cyber-hygiène “.
Bien que la pratique d’une bonne cyber-hygiène soit nécessaire, elle n’est pas suffisante. En effet, ces activités n’affectent pas l’architecture et la conception de base du système.
Principes abordés
Sans trop édulcorer ces modèles fondateurs, je propose d’envisager le pire des cas, à savoir que toutes les protections auraient échoué et que l’attaque a réussi à endommager tout ou partie du système d’information. D’autre part, je considèrerai que les sauvegardes nominales auront été corrompues.
Quel design pourrait-on mettre en place afin de pouvoir être en mesure de pouvoir reprendre l’activité au plus vite ?
Je préfèrerai ainsi mettre en avant les aspects identification, détection et restauration, en adoptant une vision plus pragmatique afin que vous puissiez appréhender les problématiques essentielles qui à mon sens doivent être abordées dans un projet de cyber-résilience.
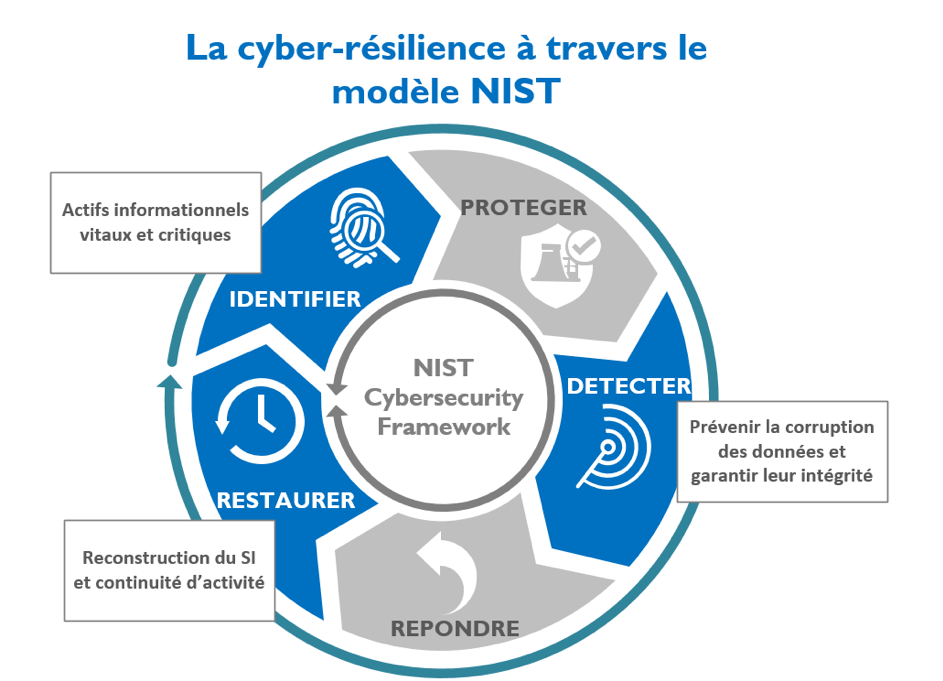
Figure 1 : aspects du disque NIST pris en compte
| Méthodologie
Déterminer le périmètre
Un gros travail est à faire avec le métier afin d’avoir une approche globale afin de déterminer quels sont les services, les applications et les données à préserver et nécessaires au bon fonctionnement de l’entreprise en cas de crise.
On pourra distinguer les données et processus vitaux, critiques et standards.
Lors de la reconstruction du SI les applications vitales peuvent être en adhérence avec des applications de moindre importance mais nécessaires en amont ou en aval afin de pouvoir fonctionner. Toute la chaîne est donc à prendre en compte lors de cette étude.
Un autre travail est à réaliser à savoir quelles sont les données dont l’entreprise va pouvoir se passer en cas de crise extrême et ceci de manière définitive.
La redondance des données ne pourra pas être l’équivalent de tout le SI pour des raisons budgétaires évidentes.
Ce point avec le métier doit être le démarrage de l’étude.
Il est parfois le plus complexe, et doit être fait avec tous les corps de métier, étant impératif de savoir à quel moment l’on doit s’arrêter lors de la phase de réplication du système.
Etablir un état des lieux
Une fois l’accent mis sur les actifs les plus critiques et la cartographie établie à l’issue, il est important de déterminer quel sera l’effort à fournir pour arriver à un SI considéré comme cyber-résilient.
Associer la nouvelle architecture au PCA
Une fois la nouvelle architecture effective, il faudra impérativement l’associer aux processus du Plan de Continuité d’Activité.
Deux points importants sont à considérer :
- Pouvoir déclencher l’isolation du système principal à tout moment et redémarrer l’activité au plus vite.
- Pouvoir continuer l’activité sans retour arrière et en toute autonomie vis-à-vis du système précédent.
| Le design de la cyber-résilience
Du design mis en œuvre dépendra la capacité de résilience du SI, je vais vous proposer un modèle qui sera détaillé tout au long de ce chapitre.
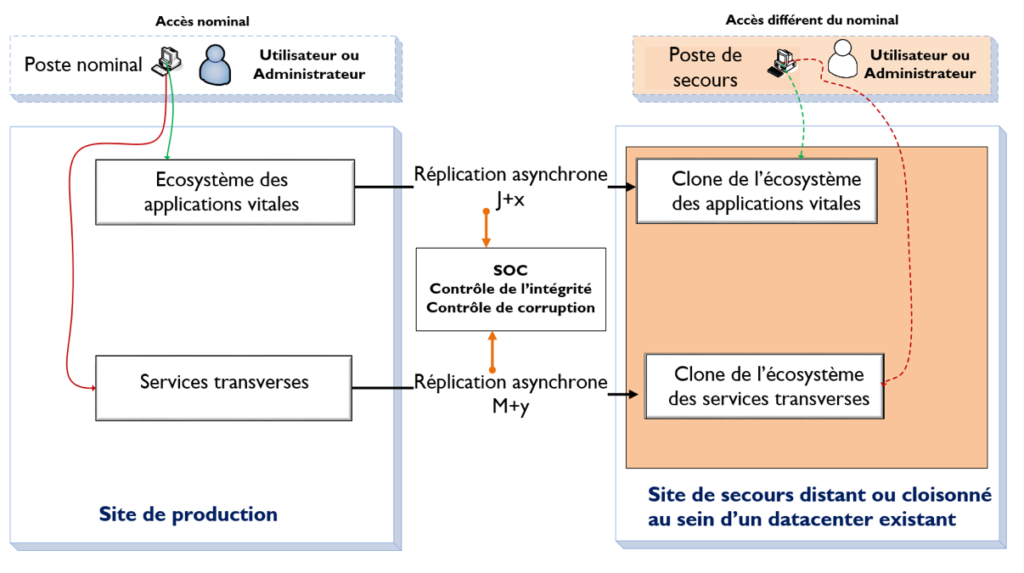
Figure 2 : proposition de modèle cyber-résilient
Création d’un système cloisonné
L’objectif premier du futur modèle est de pouvoir réduire la surface d’attaque. Le système sur lequel on va s’appuyer en cas d’attaque avérée devra être cloisonné. Plusieurs éléments d’infrastructure seront différents du SI nominal, notamment les équipements réseaux. Bien entendu, il faudra s’assurer que l’entreprise dispose des compétences adéquates à la gestion de ces nouveaux équipements.
Les accès au nouveau SI devront être différents et passer des structures réseaux et des outils d’infrastructure complètements indépendants du SI nominal.
L’administration du système répliqué devra se faire via des accès complétements autonomes et différents ; il sera fortement conseillé d’utiliser tous les renforcements nécessaires à l’authentification comme par exemple des bastions et de n’utiliser que des postes dédiés hors accès internet.
Cloud ou pas Cloud ?
Le Cloud est une bonne solution qui nécessite cependant d’être sécurisée. L’avantage est qu’il coûte moins cher qu’une infrastructure dédiée et que les machines virtuelles pourront être dans un état dormant en attendant les mises à jour ou leur activation.
Même lorsqu’il est souverain (stockage et gestion en France), il se heurte parfois à la norme comme IGI1300. Toutes les entreprises ne peuvent pas se satisfaire de cette réponse et devront passer par un système On Premise.
Mode de réplication asynchrone
La temporisation de la synchronisation va permettre un meilleur contrôle des données et garantir de ne pas subir directement leur corruption.
Dans le schéma ci-dessus, il y a deux vitesses de réplication concernant deux types de données :
- Les données métier dont la fraîcheur ne peut pas excéder quelques jours notés par la valeur x dans le schéma. Sur ces données, le risque de corruption sera le plus fort.
- Les données liées aux outils d’infrastructure dont la fraîcheur peut dater de quelques mois notés par la valeur y dans le schéma. C’est sur cette base que doit se reposer l’infrastructure résiliente, il est donc primordial de pouvoir éviter la corruption à ce niveau et de retarder au maximum la réplication de celle-ci.
La politique globale de renforcement du patch management de l’infrastructure cloisonnée restera tout de même essentielle dans ce processus et fiabilisera la réplication qui doit être sécurisée à tous les niveaux.
Il sera important de n’ouvrir le passage entre les deux systèmes que le temps des réplications et que le reste du temps il soit fermé afin de réduire encore les possibilités d’attaque.
Un SOC fort
Le processus de réplication ainsi en place ainsi que les équipements réseau mis en œuvre dans le cadre de ce processus constituent le seul SPOF de la nouvelle architecture.
Il est donc vital pour ce nouveau système de mettre en place des contrôles très poussés au niveau des données répliquées et des équipements réseau par lesquels elles transitent.
C’est pour cela que le SOC doit être impliqué dès le démarrage du projet et que tous les indicateurs doivent être opérationnels dès le premier jour de la mise en service.
| Conclusion
Ce modèle ainsi établi pourra permettre une reprise d’activité rapide.
Lorsque l’on aura réalisé ceci, deux problématiques apparaîtront :
- Le coût de la solution.
- La garantie de ne pas être corrompu.
Lorsqu’une grosse infrastructure a été mise en place depuis longtemps et que le cloisonnement n’a pas été effectué (exemple de gros Datacenters résilients sur le même réseau), les coûts de transformation seront bien entendu, très élevés. Il faudra se demander si ce coût engendré ne sera pas mineur par rapport à la perte d’activité provoquée.
Il existe désormais une prise en compte de ce paramètre par certains assureurs et on peut travailler à réduire les polices d’assurance avec les services d’actuariat de l’entreprise en fournissant la garantie que ce risque aura bien été pris en compte. Le travail réalisé pourrait être en partie financé par une réduction de la police d’assurance actuelle.
Il n’y a pas de risque zéro même dans le cas d’un design présentant les garanties d’une très bonne cyber-résilience. Cependant, la surface d’attaque sera très réduite d’une part, puisque l’on réduit les dépendances avec le SI actuel et d’autre part, le SOC sera configuré sur la réplication.
Toutes ses mesures passent par le renforcement de la sensibilisation auprès des utilisateurs et de la nécessité d’éduquer les comités directeurs de grandes entreprises afin qu’ils ne considèrent plus la sécurité comme un vecteur de coûts. Dans de nombreux cas, l’homme est le maillon faible, de sorte que tout effort de cyber-résilience doit inclure tous les mécanismes appropriés pour conduire le changement de comportement requis au sein de l’organisation.
Références
[1] https://www.enisa.europa.eu/publications/enisa-threat-landscape-report-2018 : ENISA Threat Landscape Report 2018
[2] https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-53r4.pdf : Publication du NIST : SP 800-53 Rev.4 – 2013
[3] https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-160v2.pdf : Publication du NIST : SP 800-160 Vol. 2 (Nov 2019)
[4] https://www.mitre.org/sites/default/files/publications/PR%2017-0103%20Cyber%20Resiliency%20Design%20Principles%20MTR17001.pdf : Developing Cyber Resilient Systems : A Systems Security Engineering Approach – 2017
Glossaire
APT : Advanced Persistent Threat (menace persistante avancée).
DDOS : Distributed Denial of Service attack (attaque par déni de service). Une attaque par déni de service distribué est une tentative malveillante de perturber le trafic normal vers une ressource Web.
ENISA : European Union Agency for Cybersecurity (Agence européenne chargée de la sécurité des réseaux et de l’information).
MITRE : organisation américaine à but non lucratif basée à Bedford, Massachusetts, et McLean, Virginie. Elle gère des centres de recherche et de développement (FFRDC) financés par le gouvernement fédéral et soutenant plusieurs agences gouvernementales américaines, dont le National Security Engineering Center.
NIST: National Institute of Standards and Technology.
SPoF : Single Point of Failure – point d’un système informatique dont le reste du système est dépendant et dont une panne entraîne l’arrêt complet du système.
SOC : Security Operations Center.
Tier IV : dernier échelon de classement de datacenters selon l’Uptime Institute. Ce niveau indique que le datacenter permet la tolérance aux pannes et garantie une interruption de moins d’une heure par an.


